
Chunking
Now that we know the parts of speech, we can do what is called chunking, and group words into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as "noun phrases." These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.
In order to chunk, we combine the part of speech tags with regular expressions. Mainly from regular expressions, we are going to utilize the following:
+ = match 1 or more ? = match 0 or 1 repetitions. * = match 0 or MORE repetitions . = Any character except a new line
See the tutorial linked above if you need help with regular expressions. The last things to note is that the part of speech tags are denoted with the "<" and ">" and we can also place regular expressions within the tags themselves, so account for things like "all nouns" (<N.*>)
import nltk from nltk.corpus import state_union from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt") sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content(): try: for i in tokenized: words = nltk.word_tokenize(i) tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}""" chunkParser = nltk.RegexpParser(chunkGram) chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e: print(str(e)) process_content()
The result of this is something like:
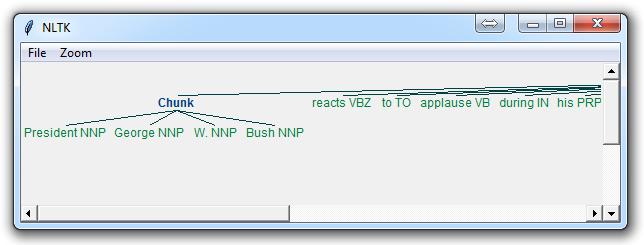
The main line here in question is:
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
This line, broken down:
<RB.?>* = "0 or more of any tense of adverb," followed by:
<VB.?>* = "0 or more of any tense of verb," followed by:
<NNP>+ = "One or more proper nouns," followed by
<NN>? = "zero or one singular noun."
Try playing around with combinations to group various instances until you feel comfortable with chunking.
Not covered in the video, but also a reasonable task is to actually access the chunks specifically. This is something rarely talked about, but can be an essential step depending on what you're doing. Say you print the chunks out, you are going to see output like:
(S
(Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP)
'S/POS
(Chunk
ADDRESS/NNP
BEFORE/NNP
A/NNP
JOINT/NNP
SESSION/NNP
OF/NNP
THE/NNP
CONGRESS/NNP
ON/NNP
THE/NNP
STATE/NNP
OF/NNP
THE/NNP
UNION/NNP
January/NNP)
31/CD
,/,
2006/CD
THE/DT
(Chunk PRESIDENT/NNP)
:/:
(Chunk Thank/NNP)
you/PRP
all/DT
./.)
Cool, that helps us visually, but what if we want to access this data via our program? Well, what is happening here is our "chunked" variable is an NLTK tree. Each "chunk" and "non chunk" is a "subtree" of the tree. We can reference these by doing something like chunked.subtrees. We can then iterate through these subtrees like so:
for subtree in chunked.subtrees(): print(subtree)
Next, we might be only interested in getting just the chunks, ignoring the rest. We can use the filter parameter in the chunked.subtrees() call.
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'): print(subtree)
Now, we're filtering to only show the subtrees with the label of "Chunk." Keep in mind, this isn't "Chunk" as in the NLTK chunk attribute... this is "Chunk" literally because that's the label we gave it here: chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
Had we said instead something like chunkGram = r"""Pythons: {<RB.?>*<VB.?>*<NNP>+<NN>?}""", then we would filter by the label of "Pythons." The result here should be something like:
- (Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP) (Chunk ADDRESS/NNP BEFORE/NNP A/NNP JOINT/NNP SESSION/NNP OF/NNP THE/NNP CONGRESS/NNP ON/NNP THE/NNP STATE/NNP OF/NNP THE/NNP UNION/NNP January/NNP) (Chunk PRESIDENT/NNP) (Chunk Thank/NNP)
Full code for this would be:
import nltk from nltk.corpus import state_union from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt") sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content(): try: for i in tokenized: words = nltk.word_tokenize(i) tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}""" chunkParser = nltk.RegexpParser(chunkGram) chunked = chunkParser.parse(tagged) print(chunked) for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'): print(subtree) chunked.draw() except Exception as e: print(str(e)) process_content()
If you get particular enough, you may find that you may be better off if there was a way to chunk everything, except some stuff. This process is what is known as chinking, and that's what we're going to be covering next.
You may find that, after a lot of chunking, you have some words in your chunk you still do not want, but you have no idea how to get rid of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk's {}.
import nltk from nltk.corpus import state_union from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt") sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content(): try: for i in tokenized[5:]: words = nltk.word_tokenize(i) tagged = nltk.pos_tag(words) chunkGram = r"""Chunk: {<.*>+} }<VB.?|IN|DT|TO>+{""" chunkParser = nltk.RegexpParser(chunkGram) chunked = chunkParser.parse(tagged) chunked.draw() except Exception as e: print(str(e)) process_content()
With this, you are given something like:
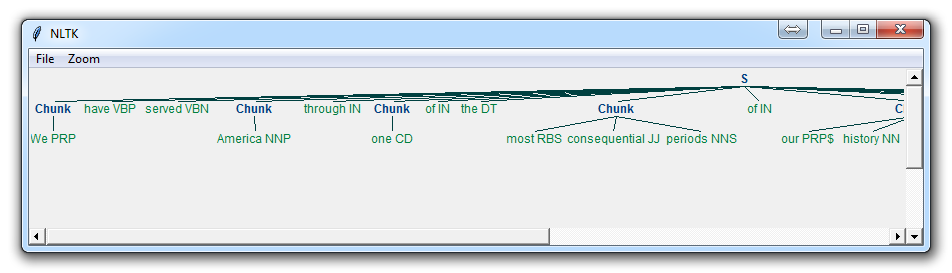
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
This means we're removing from the chink one or more verbs, prepositions, determiners, or the word 'to'.
Now that we've learned how to do some custom forms of chunking, and chinking, let's discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.
Named Entity recognition
One of the most major forms of chunking in natural language processing is called "Named Entity Recognition." The idea is to have the machine immediately be able to pull out "entities" like people, places, things, locations, monetary figures, and more.
This can be a bit of a challenge, but NLTK is this built in for us. There are two major options with NLTK's named entity recognition: either recognize all named entities, or recognize named entities as their respective type, like people, places, locations, etc.
Here's an example:
import nltk from nltk.corpus import state_union from nltk.tokenize import PunktSentenceTokenizer train_text = state_union.raw("2005-GWBush.txt") sample_text = state_union.raw("2006-GWBush.txt") custom_sent_tokenizer = PunktSentenceTokenizer(train_text) tokenized = custom_sent_tokenizer.tokenize(sample_text) def process_content(): try: for i in tokenized[5:]: words = nltk.word_tokenize(i) tagged = nltk.pos_tag(words) namedEnt = nltk.ne_chunk(tagged, binary=True) namedEnt.draw() except Exception as e: print(str(e)) process_content()
Here, with the option of binary = True, this means either something is a named entity, or not. There will be no further detail. The result is:
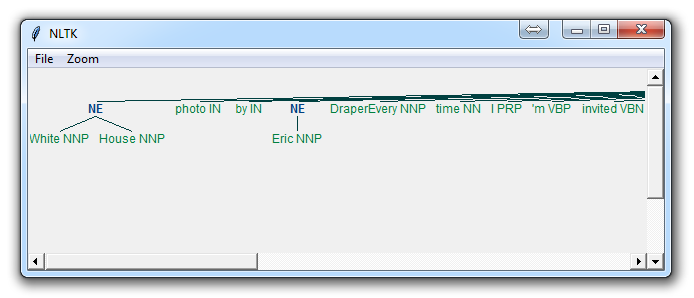
If you set binary = False, then the result is:
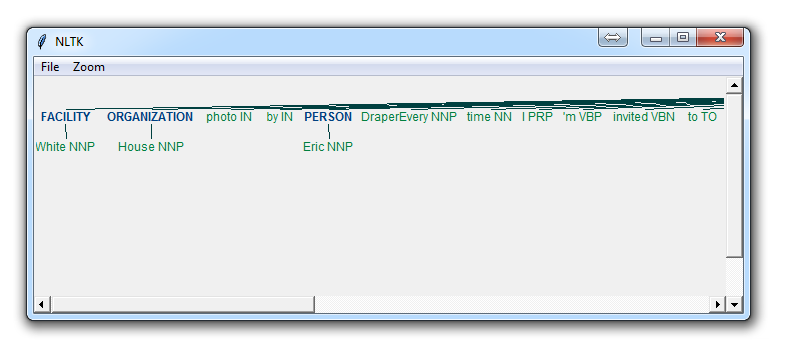
Immediately, you can see a few things. When Binary is False, it picked up the same things, but wound up splitting up terms like White House into "White" and "House" as if they were different, whereas we could see in the binary = True option, the named entity recognition was correct to say White House was part of the same named entity.
Depending on your goals, you may use the binary option how you see fit. Here are the types of Named Entities that you can get if you have binary as false:
ORGANIZATION - Georgia-Pacific Corp., WHO
PERSON - Eddy Bonte, President Obama
LOCATION - Murray River, Mount Everest
DATE - June, 2008-06-29
TIME - two fifty a m, 1:30 p.m.
MONEY - 175 million Canadian Dollars, GBP 10.40
PERCENT - twenty pct, 18.75 %
FACILITY - Washington Monument, Stonehenge
GPE - South East Asia, Midlothian
Either way, you will probably find that you need to do a bit more work to get it just right, but this is pretty powerful right out of the box.
#############################GEEKS########################
NLP | Chunking and chinking with RegEx
Chunk extraction or partial parsing is a process of meaningful extracting short phrases from the sentence (tagged with Part-of-Speech).
Chunks are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks. A ChunkRule class specifies what words or patterns to include and exclude in a chunk.
Defining Chunk patterns :
Chuck patterns are normal regular expressions which are modified and designed to match the part-of-speech tag designed to match sequences of part-of-speech tags. Angle brackets are used to specify an indiviual tag for example – to match a noun tag. One can define multiple tags in the same way.
Code #1 : Converting chunks to RegEx Pattern.
# Laading Library from nltk.chunk.regexp import tag_pattern2re_pattern # Chunk Pattern to RegEx Pattern print("Chunk Pattern : ", tag_pattern2re_pattern('<DT>?<NN.*>+')) |
Output :
Chunk Pattern : ()?(<(NN[^\{\}]*)>)+
Curly Braces are used to specify a chunk like {} and to specify the chink pattern one can just flip the braces }{. For a particular phrase type, these rules (chunk and a chink pattern) can be combined into a grammer.
Code #2 : Parsing the sentence with RegExParser.
from nltk.chunk import RegexpParser # Introducing the Pattern chunker = RegexpParser(r''' NP: {<DT><NN.*><.*>*<NN.*>} }<VB.*>{ ''') chunker.parse([('the', 'DT'), ('book', 'NN'), ( 'has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')]) |
Output :
Tree('S', [Tree('NP', [('the', 'DT'), ('book', 'NN')]), ('has', 'VBZ'),
Tree('NP', [('many', 'JJ'), ('chapters', 'NNS')])])
NLP | Chunking Rules
Below are the steps involed for Chunking –
- Conversion of sentence to a flat tree.

- Creation of Chunk string using this tree.
- Creation of RegexpChunkParser by parsing the grammer using RegexpParser.
- Appying the created chunk rule to the ChunkString that matches the sentence into a chunk.

- Splitting the bigger chunk to a smaller chunk using the defined chunk rules.

- ChunkString is then converted back to tree, with two chunk subtrees.

Code #1 : ChunkString getting modified by applying each rule.
# Loading Libraries from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule from nltk.tree import Tree # ChunkString() starts with the flat tree tree = Tree('S', [('the', 'DT'), ('book', 'NN'), ('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')]) # Initializing ChunkString() chunk_string = ChunkString(tree) print ("Chunk String : ", chunk_string) # Initializing ChunkRule chunk_rule = ChunkRule('<DT><NN.*><.*>*<NN.*>', 'chunk determiners and nouns') chunk_rule.apply(chunk_string) print ("\nApplied ChunkRule : ", chunk_string) # Another ChinkRule ir = ChinkRule('<VB.*>', 'chink verbs') ir.apply(chunk_string) print ("\nApplied ChinkRule : ", chunk_string, "\n") # Back to chunk sub-tree chunk_string.to_chunkstruct() |
Output:
Chunk String : <<DT> <NN> <VBZ> <JJ> <NNS>
Applied ChunkRule : {<DT> <NN> <VBZ> <JJ> <NNS>}
Applied ChinkRule : {<DT> <NN>} <VBZ> {<JJ> <NNS>}
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])])
Note : This code works exactly in the same manner as explained in the ChunkRule steps above.
Code #2 : How to this task directly with RegexpChunkParser.
# Loading Libraries from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule from nltk.tree import Tree from nltk.chunk import RegexpChunkParser # ChunkString() starts with the flat tree tree = Tree('S', [('the', 'DT'), ('book', 'NN'), ('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')]) # Initializing ChunkRule chunk_rule = ChunkRule('<DT><NN.*><.*>*<NN.*>', 'chunk determiners and nouns') # Another ChinkRule chink_rule = ChinkRule('<VB.*>', 'chink verbs') # Applying RegexpChunkParser chunker = RegexpChunkParser([chunk_rule, chink_rule]) chunker.parse(tree) |
Output:
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('book', 'NN')]),
('has', 'VBZ'), Tree('CHUNK', [('many', 'JJ'), ('chapters', 'NNS')])])
Code #3 : Parsing with different ChunkType.
# Loading Libraries from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule from nltk.tree import Tree from nltk.chunk import RegexpChunkParser # ChunkString() starts with the flat tree tree = Tree('S', [('the', 'DT'), ('book', 'NN'), ('has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')]) # Initializing ChunkRule chunk_rule = ChunkRule('<DT><NN.*><.*>*<NN.*>', 'chunk determiners and nouns') # Another ChinkRule chink_rule = ChinkRule('<VB.*>', 'chink verbs') # Applying RegexpChunkParser chunker = RegexpChunkParser([chunk_rule, chink_rule], chunk_label ='CP') chunker.parse(tree) |
Output:
Tree('S', [Tree('CP', [('the', 'DT'), ('book', 'NN')]), ('has', 'VBZ'),
Tree('CP', [('many', 'JJ'), ('chapters', 'NNS')])])
NLP | Chunking and chinking with RegEx
Chunk extraction or partial parsing is a process of meaningful extracting short phrases from the sentence (tagged with Part-of-Speech).
Chunks are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks. A ChunkRule class specifies what words or patterns to include and exclude in a chunk.
Defining Chunk patterns :
Chuck patterns are normal regular expressions which are modified and designed to match the part-of-speech tag designed to match sequences of part-of-speech tags. Angle brackets are used to specify an indiviual tag for example – to match a noun tag. One can define multiple tags in the same way.
Code #1 : Converting chunks to RegEx Pattern.
# Laading Library from nltk.chunk.regexp import tag_pattern2re_pattern # Chunk Pattern to RegEx Pattern print("Chunk Pattern : ", tag_pattern2re_pattern('<DT>?<NN.*>+')) |
Output :
Chunk Pattern : ()?(<(NN[^\{\}]*)>)+
Curly Braces are used to specify a chunk like {} and to specify the chink pattern one can just flip the braces }{. For a particular phrase type, these rules (chunk and a chink pattern) can be combined into a grammer.
Code #2 : Parsing the sentence with RegExParser.
from nltk.chunk import RegexpParser # Introducing the Pattern chunker = RegexpParser(r''' NP: {<DT><NN.*><.*>*<NN.*>} }<VB.*>{ ''') chunker.parse([('the', 'DT'), ('book', 'NN'), ( 'has', 'VBZ'), ('many', 'JJ'), ('chapters', 'NNS')]) |
Output :
Tree('S', [Tree('NP', [('the', 'DT'), ('book', 'NN')]), ('has', 'VBZ'),
Tree('NP', [('many', 'JJ'), ('chapters', 'NNS')])])
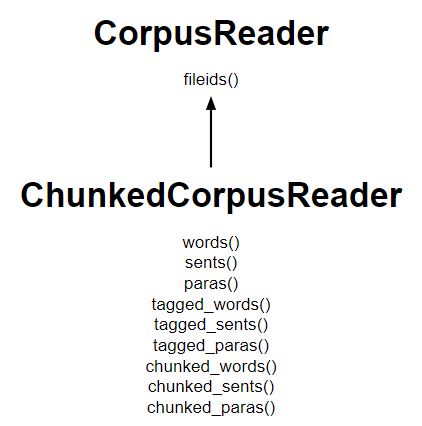
NLP | Chunking using Corpus Reader
What are Chunks?
These are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks. A ChunkRule class specifies what words or patterns to include and exclude in a chunk.
How it works :
- The ChunkedCorpusReader class works similar to the TaggedCorpusReader for getting tagged tokens, plus it also provides three new methods for getting chunks.
- An instance of nltk.tree.Tree represents each chunk.
- Noun phrase trees look like Tree(‘NP’, […]) where as Sentence level trees look like Tree(‘S’, […]).
- A list of sentence trees, with each noun phrase as a subtree of the sentence is obtained in n chunked_sents()
- A list of noun phrase trees alongside tagged tokens of words that were not in a chunk is obtained in chunked_words().
Diagram listing the major methods:
Code #1 : Creating a ChunkedCorpusReader for words
# Using ChunkedCorpusReader from nltk.corpus.reader import ChunkedCorpusReader # intitializing x = ChunkedCorpusReader('.', r'.*\.chunk') words = x.chunked_words() print ("Words : \n", words) |
Output :
Words :
[Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ...]
Code #2 : For sentence
Chunked Sentence = x.chunked_sents() print ("Chunked Sentence : \n", tagged_sent) |
Output :
Chunked Sentence :
[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]
Code #3 : For paragraphs
para = x.chunked_paras()() print ("para : \n", para) |
Output :
[[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction',
'NN'), ('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'),
('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]]
NLP | Classifier-based Chunking | Set 1
The ClassifierBasedTagger class learns from the features, unlike most part-of-speech taggers. ClassifierChunker class can be created such that it can learn from both the words and part-of-speech tags, instead of just from the part-of-speech tags as the TagChunker class does.
The (word, pos, iob) 3-tuples is converted into ((word, pos), iob) 2-tuples using the chunk_trees2train_chunks() from tree2conlltags(), to remain compatible with the 2-tuple (word, pos) format required for training a ClassiferBasedTagger class.
Code #1 : Let’s understand
# Loading Libraries from nltk.chunk import ChunkParserI from nltk.chunk.util import tree2conlltags, conlltags2tree from nltk.tag import ClassifierBasedTagger def chunk_trees2train_chunks(chunk_sents): # Using tree2conlltags tag_sents = [tree2conlltags(sent) for sent in chunk_sents] 3-tuple is converted to 2-tuple return [[((w, t), c) for (w, t, c) in sent] for sent in tag_sents] |
Now, a feature detector function is needed to pass into ClassifierBasedTagger. Any feature detector function used with the ClassifierChunker class (defined next) should recognize that tokens are a list of (word, pos) tuples, and have the same function signature as prev_next_pos_iob(). To give the classifier as much information as we can, this feature set contains the current, previous, and next word and part-of-speech tag, along with the previous IOB tag.
Code #2 : detector function
def prev_next_pos_iob(tokens, index, history): word, pos = tokens[index] if index == 0: prevword, prevpos, previob = ('<START>', )*3 else: prevword, prevpos = tokens[index-1] previob = history[index-1] if index == len(tokens) - 1: nextword, nextpos = ('<END>', )*2 else: nextword, nextpos = tokens[index + 1] feats = {'word': word, 'pos': pos, 'nextword': nextword, 'nextpos': nextpos, 'prevword': prevword, 'prevpos': prevpos, 'previob': previob } return feats |
Now, ClassifierChunker class is need which uses an internal ClassifierBasedTagger with training sentences from chunk_trees2train_chunks() and features extracted using prev_next_pos_iob(). As a subclass of ChunkerParserI, ClassifierChunker implements the parse() method to convert the ((w, t), c) tuples, produced by the internal tagger into Trees using conlltags2tree()
Code #3 :
class ClassifierChunker(ChunkParserI): def __init__(self, train_sents, feature_detector = prev_next_pos_iob, **kwargs): if not feature_detector: feature_detector = self.feature_detector train_chunks = chunk_trees2train_chunks(train_sents) self.tagger = ClassifierBasedTagger(train = train_chunks, feature_detector = feature_detector, **kwargs) def parse(self, tagged_sent): if not tagged_sent: return Nonechunks = self.tagger.tag(tagged_sent) return conlltags2tree( [(w, t, c) for ((w, t), c) in chunks]) |
NLP | Classifier-based Chunking | Set 2
Using the data from the treebank_chunk corpus let us evaluate the chunkers (prepared in the previous article).
Code #1 :
# loading libraries from chunkers import ClassifierChunker from nltk.corpus import treebank_chunk train_data = treebank_chunk.chunked_sents()[:3000] test_data = treebank_chunk.chunked_sents()[3000:] # initializing chunker = ClassifierChunker(train_data) # evaluation score = chunker.evaluate(test_data) a = score.accuracy() p = score.precision() r = recall print ("Accuracy of ClassifierChunker : ", a) print ("\nPrecision of ClassifierChunker : ", p) print ("\nRecall of ClassifierChunker : ", r) |
Output :
Accuracy of ClassifierChunker : 0.9721733155838022 Precision of ClassifierChunker : 0.9258838793383068 Recall of ClassifierChunker : 0.9359016393442623
Code #2 : Let’s compare the performance of conll_train
chunker = ClassifierChunker(conll_train) score = chunker.evaluate(conll_test) a = score.accuracy() p = score.precision() r = score.recall() print ("Accuracy of ClassifierChunker : ", a) print ("\nPrecision of ClassifierChunker : ", p) print ("\nRecall of ClassifierChunker : ", r) |
Output :
Accuracy of ClassifierChunker : 0.9264622074002153 Precision of ClassifierChunker : 0.8737924310910219 Recall of ClassifierChunker : 0.9007354620620346
the word can be passed through the tagger into our feature detector function, by creating nested 2-tuples of the form ((word, pos), iob), The chunk_trees2train_chunks() method produces these nested 2-tuples.
The following features are extracted:
- The current word and part-of-speech tag
- The previous word and IOB tag, part-of-speech tag
- The next word and part-of-speech tag
The ClassifierChunker class uses an internal ClassifierBasedTagger and prev_next_pos_iob() as its default feature_detector. The results from the tagger, which are in the same nested 2-tuple form, are then reformated into 3-tuples to return a final Tree using conlltags2tree().
Code #3 : different classifier builder
# loading libraries from chunkers import ClassifierChunker from nltk.corpus import treebank_chunk from nltk.classify import MaxentClassifier train_data = treebank_chunk.chunked_sents()[:3000] test_data = treebank_chunk.chunked_sents()[3000:] builder = lambda toks: MaxentClassifier.train( toks, trace = 0, max_iter = 10, min_lldelta = 0.01) chunker = ClassifierChunker( train_data, classifier_builder = builder) score = chunker.evaluate(test_data) a = score.accuracy() p = score.precision() r = score.recall() print ("Accuracy of ClassifierChunker : ", a) print ("\nPrecision of ClassifierChunker : ", p) print ("\nRecall of ClassifierChunker : ", r) |
Output :
Accuracy of ClassifierChunker : 0.9743204362949285 Precision of ClassifierChunker : 0.9334423548650859 Recall of ClassifierChunker : 0.9357377049180328
ClassifierBasedTagger class defaults to using NaiveBayesClassifier.train as its classifier_builder. But any classifier can be used by overriding the classifier_builder keyword argument.
NLP | Distributed chunking with Execnet
The article aims to perform chunking and tagging over an execnet gateway. Here two objects will be sent instead of one, and a Tree is received, which requires pickling and unpickling for serialization.
How it works ?
- Use a pickled tagger.
- First, pickle the default chunker used by nltk.chunk.ne_chunk(), though any chunker would do.
- Next, make a gateway for the remote_chunk module, get a channel, and send the pickled tagger and chunker over.
- Then, receive a pickled Tree, which can be unpickled and inspected to see the result. Finally, exit the gateway:
Code : Explaining the working
# importing libraries import execnet, remote_chunk import nltk.data, nltk.tag, nltk.chunk import pickle from nltk.corpus import treebank_chunk tagger = pickle.dumps(nltk.data.load(nltk.tag._POS_TAGGER)) chunker = pickle.dumps( nltk.data.load(nltk.chunk._MULTICLASS_NE_CHUNKER)) gw = execnet.makegateway() channel = gw.remote_exec(remote_chunk) channel.send(tagger) channel.send(chunker) channel.send(treebank_chunk.sents()[0]) chunk_tree = pickle.loads(channel.receive()) print (chunk_tree) gw.exit() |
Output :
Tree('S', [Tree('PERSON', [('Pierre', 'NNP')]), Tree('ORGANIZATION',
[('Vinken', 'NNP')]), (', ', ', '), ('61', 'CD'), ('years', 'NNS'),
('old', 'JJ'), (', ', ', '), ('will', 'MD'), ('join', 'VB'), ('the',
'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive',
'JJ'), ('director', 'NN'), ('Nov.', 'NNP'), ('29', 'CD'), ('.', '.')])
Communication this time is slightly different as in figure given below –
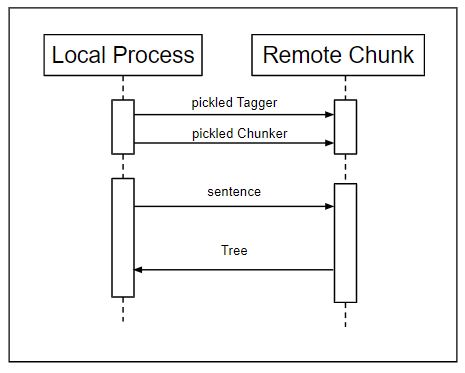
- The remote_chunk.py module is just a little bit more complicated than the remote_tag.py module.
- In addition to receiving a pickled tagger, it also expects to receive a pickled chunker that implements the ChunkerIinterface
- Once it has both a tagger and a chunker, it expects to receive any number of tokenized sentences, which it tags and parses into a Tree. This Tree is then pickled and sent back over the channel:
Code : Explaining the above working
import pickle if __name__ == '__channelexec__': tagger = pickle.loads(channel.receive()) chunker = pickle.loads(channel.receive()) for sentence in channel: chunk_tree = chunker.parse(tagger.tag(sent)) channel.send(pickle.dumps(chunk_tree)) |
remote_chunk module’s only external dependency is the pickle module, which is part of the Python standard library. It doesn’t need to import any NLTK modules in order to use the tagger or chunker, because all the necessary data is pickled and sent over the channel.