
In our path to learning how to do sentiment analysis with NLTK, we're going to learn the following:
- Tokenizing - Splitting sentences and words from the body of text.
- Part of Speech tagging
- Machine Learning with the Naive Bayes classifier
- How to tie in Scikit-learn (sklearn) with NLTK
- Training classifiers with data sets
- Performing live, streaming, sentiment analysis with Twitter.
- ...and much more.
In order to get started, you are going to need the NLTK module, as well as Python.
Next, you're going to need NLTK 3. The easiest method to installing the NLTK module is going to be with pip.
For all users, that is done by opening up cmd.exe, bash, or whatever shell you use and typing:
pip install nltk
Next, we need to install some of the components for NLTK. Open python via whatever means you normally do, and type:
import nltk nltk.download()
Unless you are operating headless, a GUI will pop up like this, only probably with red instead of green:
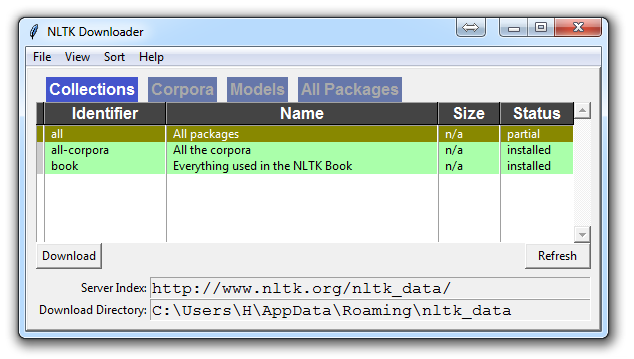
Choose to download "all" for all packages, and then click 'download.' This will give you all of the tokenizers, chunkers, other algorithms, and all of the corpora. If space is an issue, you can elect to selectively download everything manually. The NLTK module will take up about 7MB, and the entire nltk_data directory will take up about 1.8GB, which includes your chunkers, parsers, and the corpora.
If you are operating headless, like on a VPS, you can install everything by running Python and doing:
import nltk
nltk.download()
d (for download)
all (for download everything)
That will download everything for you headlessly.
Now that you have all the things that you need, let's knock out some quick vocabulary:
- Corpus - Body of text, singular. Corpora is the plural of this. Example: A collection of medical journals.
- Lexicon - Words and their meanings. Example: English dictionary. Consider, however, that various fields will have different lexicons. For example: To a financial investor, the first meaning for the word "Bull" is someone who is confident about the market, as compared to the common English lexicon, where the first meaning for the word "Bull" is an animal. As such, there is a special lexicon for financial investors, doctors, children, mechanics, and so on.
- Token - Each "entity" that is a part of whatever was split up based on rules. For examples, each word is a token when a sentence is "tokenized" into words. Each sentence can also be a token, if you tokenized the sentences out of a paragraph.
These are the words you will most commonly hear upon entering the Natural Language Processing (NLP) space, but there are many more that we will be covering in time. With that, let's show an example of how one might actually tokenize something into tokens with the NLTK module.
from nltk.tokenize import sent_tokenize, word_tokenize EXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard." print(sent_tokenize(EXAMPLE_TEXT))
At first, you may think tokenizing by things like words or sentences is a rather trivial enterprise. For many sentences it can be. The first step would be likely doing a simple .split('. '), or splitting by period followed by a space. Then maybe you would bring in some regular expressions to split by period, space, and then a capital letter. The problem is that things like Mr. Smith would cause you trouble, and many other things. Splitting by word is also a challenge, especially when considering things like concatenations like we and are to we're. NLTK is going to go ahead and just save you a ton of time with this seemingly simple, yet very complex, operation.
The above code will output the sentences, split up into a list of sentences, which you can do things like iterate through with a for loop.
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]
So there, we have created tokens, which are sentences. Let's tokenize by word instead this time:
print(word_tokenize(EXAMPLE_TEXT))
Now our output is: ['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
There are a few things to note here. First, notice that punctuation is treated as a separate token. Also, notice the separation of the word "shouldn't" into "should" and "n't." Finally, notice that "pinkish-blue" is indeed treated like the "one word" it was meant to be turned into. Pretty cool!
Now, looking at these tokenized words, we have to begin thinking about what our next step might be. We start to ponder about how might we derive meaning by looking at these words. We can clearly think of ways to put value to many words, but we also see a few words that are basically worthless. These are a form of "stop words," which we can also handle for. That is what we're going to be talking about in the next tutorial.
Tokenize text using NLTK in python
To run the below python program, (NLTK) natural language toolkit has to be installed in your system.
The NLTK module is a massive tool kit, aimed at helping you with the entire Natural Language Processing (NLP) methodology.
In order to install NLTK run the following commands in your terminal.
- sudo pip install nltk
- Then, enter the python shell in your terminal by simply typing python
- Type import nltk
- nltk.download(‘all’)
The above installation will take quite some time due to the massive amount of tokenizers, chunkers, other algorithms, and all of the corpora to be downloaded.
-
- Some terms that will be frequently used are :
-
- Corpus – Body of text, singular. Corpora is the plural of this.
- Lexicon – Words and their meanings.
- Token – Each “entity” that is a part of whatever was split up based on rules. For examples, each word is a token when a sentence is “tokenized” into words. Each sentence can also be a token, if you tokenized the sentences out of a paragraph.
So basically tokenizing involves splitting sentences and words from the body of the text.
# import the existing word and sentence tokenizing # libraries from nltk.tokenize import sent_tokenize, word_tokenize text = "Natural language processing (NLP) is a field " + \ "of computer science, artificial intelligence " + \ "and computational linguistics concerned with " + \ "the interactions between computers and human " + \ "(natural) languages, and, in particular, " + \ "concerned with programming computers to " + \ "fruitfully process large natural language " + \ "corpora. Challenges in natural language " + \ "processing frequently involve natural " + \ "language understanding, natural language" + \ "generation frequently from formal, machine" + \ "-readable logical forms), connecting language " + \ "and machine perception, managing human-" + \ "computer dialog systems, or some combination " + \ "thereof." print(sent_tokenize(text)) print(word_tokenize(text))` |
OUTPUT
[‘Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics concerned with the interactions between computers and human (natural) languages, and, in particular, concerned with programming computers to fruitfully process large natural language corpora.’, ‘Challenges in natural language processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, managing human-computer dialog systems, or some combination thereof.’]
[‘Natural’, ‘language’, ‘processing’, ‘(‘, ‘NLP’, ‘)’, ‘is’, ‘a’, ‘field’, ‘of’, ‘computer’, ‘science’, ‘,’, ‘artificial’, ‘intelligence’, ‘and’, ‘computational’, ‘linguistics’, ‘concerned’, ‘with’, ‘the’, ‘interactions’, ‘between’, ‘computers’, ‘and’, ‘human’, ‘(‘, ‘natural’, ‘)’, ‘languages’, ‘,’, ‘and’, ‘,’, ‘in’, ‘particular’, ‘,’, ‘concerned’, ‘with’, ‘programming’, ‘computers’, ‘to’, ‘fruitfully’, ‘process’, ‘large’, ‘natural’, ‘language’, ‘corpora’, ‘.’, ‘Challenges’, ‘in’, ‘natural’, ‘language’, ‘processing’, ‘frequently’, ‘involve’, ‘natural’, ‘language’, ‘understanding’, ‘,’, ‘natural’, ‘language’, ‘generation’, ‘(‘, ‘frequently’, ‘from’, ‘formal’, ‘,’, ‘machine-readable’, ‘logical’, ‘forms’, ‘)’, ‘,’, ‘connecting’, ‘language’, ‘and’, ‘machine’, ‘perception’, ‘,’, ‘managing’, ‘human-computer’, ‘dialog’, ‘systems’, ‘,’, ‘or’, ‘some’, ‘combination’, ‘thereof’, ‘.’]
So there, we have created tokens, which are sentences initially and words later.
Python NLTK | nltk.tokenizer.word_tokenize()
With the help of nltk.tokenize.word_tokenize() method, we are able to extract the tokens from string of characters by using tokenize.word_tokenize() method. It actually returns the syllables from a single word. A single word can contain one or two syllables.
Syntax :
tokenize.word_tokenize()
Return : Return the list of syllables of words.
Example #1 :
In this example we can see that by using tokenize.word_tokenize() method, we are able to extract the syllables from stream of words or sentences.
# import SyllableTokenizer() method from nltk from nltk import word_tokenize # Create a reference variable for Class word_tokenize tk = SyllableTokenizer() # Create a string input gfg = "Antidisestablishmentarianism" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘An’, ‘ti’, ‘dis’, ‘es’, ‘ta’, ‘blish’, ‘men’, ‘ta’, ‘ria’, ‘nism’]
Example #2 :
# import SyllableTokenizer() method from nltk from nltk.tokenize import word_tokenize # Create a reference variable for Class word_tokenize tk = SyllableTokenizer() # Create a string input gfg = "Gametophyte" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘Ga’, ‘me’, ‘to’, ‘phy’, ‘te’]
Python NLTK | tokenize.WordPunctTokenizer()
With the help of nltk.tokenize.WordPunctTokenizer()() method, we are able to extract the tokens from string of words or sentences in the form of Alphabetic and Non-Alphabetic character by using tokenize.WordPunctTokenizer()() method.
Syntax :
tokenize.WordPunctTokenizer()()
Return : Return the tokens from a string of alphabetic or non-alphabetic character.
Example #1 :
In this example we can see that by using tokenize.WordPunctTokenizer()() method, we are able to extract the tokens from stream of alphabetic or non-alphabetic character.
# import WordPunctTokenizer() method from nltk from nltk.tokenize import WordPunctTokenizer # Create a reference variable for Class WordPunctTokenizer tk = WordPunctTokenizer() # Create a string input gfg = "GeeksforGeeks...$$&* \nis\t for geeks" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘GeeksforGeeks’, ‘…$$&*’, ‘is’, ‘for’, ‘geeks’]
Example #2 :
# import WordPunctTokenizer() method from nltk from nltk.tokenize import WordPunctTokenizer # Create a reference variable for Class WordPunctTokenizer tk = WordPunctTokenizer() # Create a string input gfg = "The price\t of burger \nin BurgerKing is Rs.36.\n" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘The’, ‘price’, ‘of’, ‘burger’, ‘in’, ‘BurgerKing’, ‘is’, ‘Rs’, ‘.’, ’36’, ‘.’]
Python NLTK | nltk.tokenize.SpaceTokenizer()
With the help of nltk.tokenize.SpaceTokenizer() method, we are able to extract the tokens from string of words on the basis of space between them by using tokenize.SpaceTokenizer() method.
Syntax :
tokenize.SpaceTokenizer()
Return : Return the tokens of words.
Example #1 :
In this example we can see that by using tokenize.SpaceTokenizer() method, we are able to extract the tokens from stream to words having space between them.
# import SpaceTokenizer() method from nltk from nltk.tokenize import SpaceTokenizer # Create a reference variable for Class SpaceTokenizer tk = SpaceTokenizer() # Create a string input gfg = "Geeksfor Geeks.. .$$&* \nis\t for geeks" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘Geeksfor’, ‘Geeks..’, ‘.$$&*’, ‘\nis\t’, ‘for’, ‘geeks’]
Example #2 :
# import SpaceTokenizer() method from nltk from nltk.tokenize import SpaceTokenizer # Create a reference variable for Class SpaceTokenizer tk = SpaceTokenizer() # Create a string input gfg = "The price\t of burger \nin BurgerKing is Rs.36.\n" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘The’, ‘price\t’, ‘of’, ‘burger’, ‘\nin’, ‘BurgerKing’, ‘is’, ‘Rs.36.\n’]
Python NLTK | nltk.tokenize.LineTokenizer
With the help of nltk.tokenize.LineTokenizer() method, we are able to extract the tokens from string of sentences in the form of single line by using tokenize.LineTokenizer() method.
Syntax :
tokenize.LineTokenizer()
Return : Return the tokens of line from stream of sentences.
Example #1 :
In this example we can see that by using tokenize.LineTokenizer() method, we are able to extract the tokens from stream of sentences into small lines.
# import LineTokenizer() method from nltk from nltk.tokenize import LineTokenizer # Create a reference variable for Class LineTokenizer tk = LineTokenizer() # Create a string input gfg = "GeeksforGeeks...$$&* \nis\n for geeks" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘GeeksforGeeks…$$&* ‘, ‘is’, ‘ for geeks’]
Example #2 :
# import LineTokenizer() method from nltk from nltk.tokenize import LineTokenizer # Create a reference variable for Class LineTokenizer tk = LineTokenizer(blanklines ='keep') # Create a string input gfg = "The price\n\n of burger \nin BurgerKing is Rs.36.\n" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘The price’, ”, ‘ of burger ‘, ‘in BurgerKing is Rs.36.’]
Python NLTK | tokenize.regexp()
With the help of NLTK tokenize.regexp() module, we are able to extract the tokens from string by using regular expression with RegexpTokenizer() method.
Syntax :
tokenize.RegexpTokenizer()
Return : Return array of tokens using regular expression
Example #1 :
In this example we are using RegexpTokenizer() method to extract the stream of tokens with the help of regular expressions.
# import RegexpTokenizer() method from nltk from nltk.tokenize import RegexpTokenizer # Create a reference variable for Class RegexpTokenizer tk = RegexpTokenizer('\s+', gaps = True) # Create a string input gfg = "I love Python" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘I’, ‘love’, ‘Python’]
Example #2 :
# import RegexpTokenizer() method from nltk from nltk.tokenize import RegexpTokenizer # Create a reference variable for Class RegexpTokenizer tk = RegexpTokenizer('\s+', gaps = True) # Create a string input gfg = "Geeks for Geeks" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘Geeks’, ‘for’, ‘Geeks’]
Python NLTK | nltk.TweetTokenizer()
With the help of NLTK nltk.TweetTokenizer() method, we are able to convert the stream of words into small small tokens so that we can analyse the audio stream with the help of nltk.TweetTokenizer() method.
Syntax :
nltk.TweetTokenizer()
Return : Return the stream of token
Example #1 :
In this example when we pass audio stream in the form of string it will converted to small tokens from a long string with the help of nltk.TweetTokenizer() method.
# import TweetTokenizer() method from nltk from nltk.tokenize import TweetTokenizer # Create a reference variable for Class TweetTokenizer tk = TweetTokenizer() # Create a string input gfg = "Geeks for Geeks" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘Geeks’, ‘for’, ‘Geeks’]
Example #2 :
# import TweetTokenizer() method from nltk from nltk.tokenize import TweetTokenizer # Create a reference variable for Class TweetTokenizer tk = TweetTokenizer() # Create a string input gfg = ":-) <> () {} [] :-p" # Use tokenize method geek = tk.tokenize(gfg) print(geek) |
Output :
[‘:-)’, ”, ‘(‘, ‘)’, ‘{‘, ‘}’, ‘[‘, ‘]’, ‘:-p’]