
In this SQL tutorial, you’ll learn all the basic to advanced SQL concepts like SQL queries, SQL join, SQL injection, SQL insert, and creating tables in SQL. SQL is easy to learn, there are no prerequisites to learn SQL.
So, SQL is a standard database language used to access and manipulate data in databases. SQL stands for Structured Query Language. It was developed by IBM Computer Scientists in the 1970s. By executing queries SQL can create, update, delete, and retrieve data in databases like MySQL, Oracle, PostgreSQL, etc. Overall, SQL is a query language that communicates with databases.
What is a Database?
Before deep diving into this free SQL tutorial, let’s understand what a database is.
So, data is the new fuel of this world, but data is unorganized information, so to organize that data, we make a database. A database is an organized collection of structured data, usually controlled by a database management system (DBMS). Databases help us easily store, access, and manipulate data held on a computer.
SQL Example
In this detailed SQL tutorial for beginners, we’ll explore practical SQL examples for managing employee data within a database. We’ll create a table to store employee information and populate it with sample data like Employee_Id, Name, Age, Department, and Salary.

If you want to retrieves data from the employees table where the salary is greater than 55000.00 then we will use SELECT Statement.
Query:
SELECT * FROM employees WHERE Salary > 55000.00;
Output:

Explanation:
This SELECT statement retrieves records from the employees table where the Salary column is greater than 55000.00. The * symbol indicates that we want to retrieve all columns for the matching records. The WHERE clause filters the results based on the specified condition.
Why to Learn SQL?
SQL helps you to easily get information from data with high efficiency. To manipulate the data in databases like Create, Read, Edit, and Delete, we use SQL queries. Users can interact with data stored in relational database management systems. Anyone who knows the English language can easily write SQL queries. Some of the key features of SQL are given below:
- Without a lot of coding knowledge, we can manage a database with SQL.
- SQL works with database systems from Oracle, IBM, Microsoft, etc.
- Simple and easy to learn.
- SQL is an ANSI and ISO standard language for database manipulation.
- SQL retrieves large amounts of data very fast.
Pre-Requisites to Learn SQL
If you want to learn SQL then, this free SQL tutorial is quite easy to understand because, during the development of this course, we tried our best to provide the best resource to clear your SQL concept.
But we assume that you are already aware of the basic conceptions of computer science, like databases and its types.
So, if you have basic knowledge of RDBMS, then this SQL tutorial provides you with enough knowledge to master SQL.
Types of Databases
A quick review of the present need to store massive chunks of data relevant to multiple related or unrelated categories, reveals that databases must be highly effective at what they are designed to do.
This is not only because of the amount of data being continuously revised or modified that we are dealing with the dynamics of it aren’t of sole interest anymore. It’s because of the social value that every individual has assigned to them: databases are the literal backbone of a client’s lifestyle or a business’s worth.
Designing different types of databases lies at the core of the functionality that they provide to the users. Since data is a dynamic entity, the way it is stored varies a lot. It is also the reason behind companies designing their own types of databases that comply with their needs. In this article, we will be discussing the types of Databases in detail.
Types of Databases
There are several types of databases, that are briefly explained below.
- Hierarchical databases
- Network databases
- Object-oriented databases
- Relational databases
- Cloud Database
- Centralized Database
- Operational Database
- NoSQL databases
Hierarchical Databases
Just as in any hierarchy, this database follows the progression of data being categorized in ranks or levels, wherein data is categorized based on a common point of linkage. As a result, two entities of data will be lower in rank and the commonality would assume a higher rank. Refer to the diagram below:
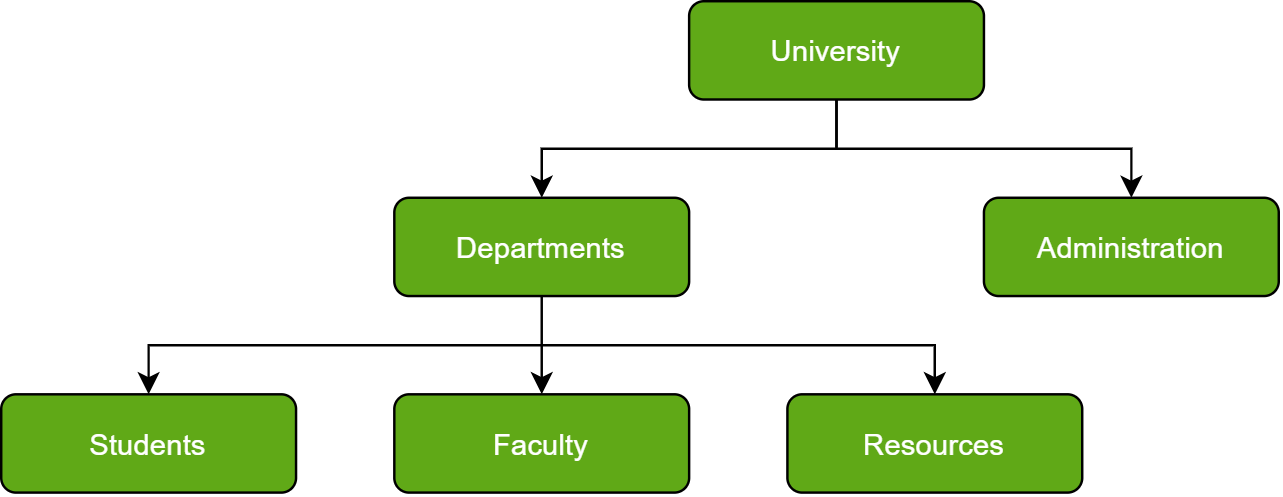
Hierarchical Database Example
Do note how Departments and Administration are entirely unlike each other and yet fall under the domain of a University. They are elements that form this hierarchy.
Another perspective advises visualizing the data being organized in a parent-child relationship, which upon addition of multiple data elements would resemble a tree. The child records are linked to the parent record using a field, and so the parent record is allowed multiple child records. However, vice versa is not possible.
Notice that due to such a structure, hierarchical databases are not easily scalable; the addition of data elements requires a lengthy traversal through the database.
Network Databases
In Layman’s terms, a network database is a hierarchical database, but with a major tweak. The child records are given the freedom to associate with multiple parent records. As a result, a network or net of database files linked with multiple threads is observed. Notice how the Student, Faculty, and Resources elements each have two-parent records, which are Departments and Clubs.
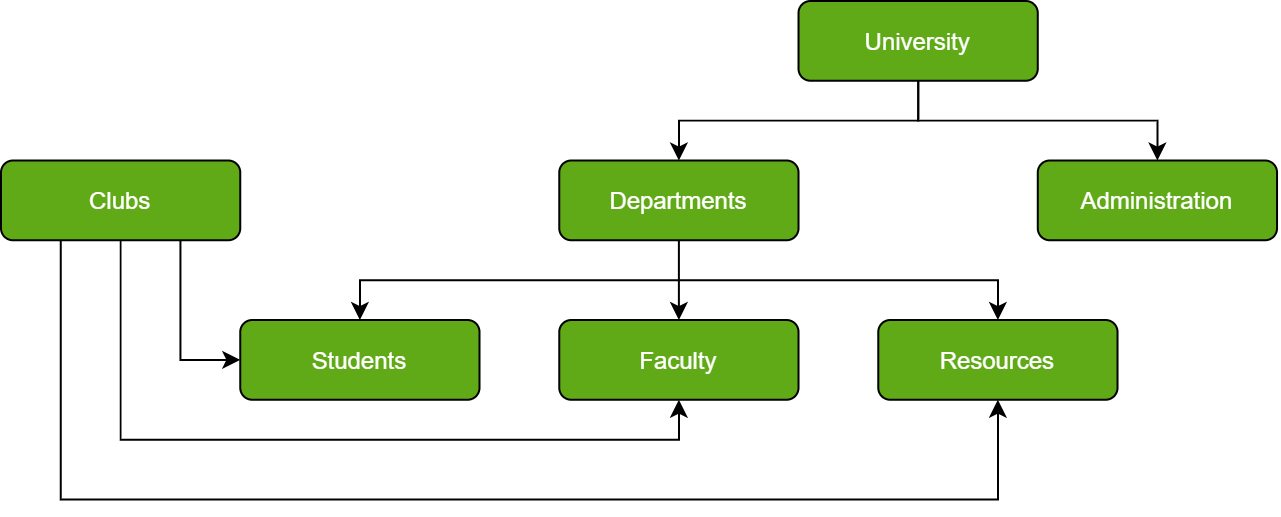
Network Database Example
Certainly, a complex framework, network databases are more capable of representing two-directional relationships. Also, conceptual simplicity favors the utilization of a simpler database management language.
The disadvantage lies in the inability to alter the structure due to its complexity and also in it being highly structurally dependent.
Object-Oriented Databases
Those familiar with the Object-Oriented Programming Paradigm would be able to relate to this model of databases easily. Information stored in a database is capable of being represented as an object which response as an instance of the database model. Therefore, the object can be referenced and called without any difficulty. As a result, the workload on the database is substantially reduced.
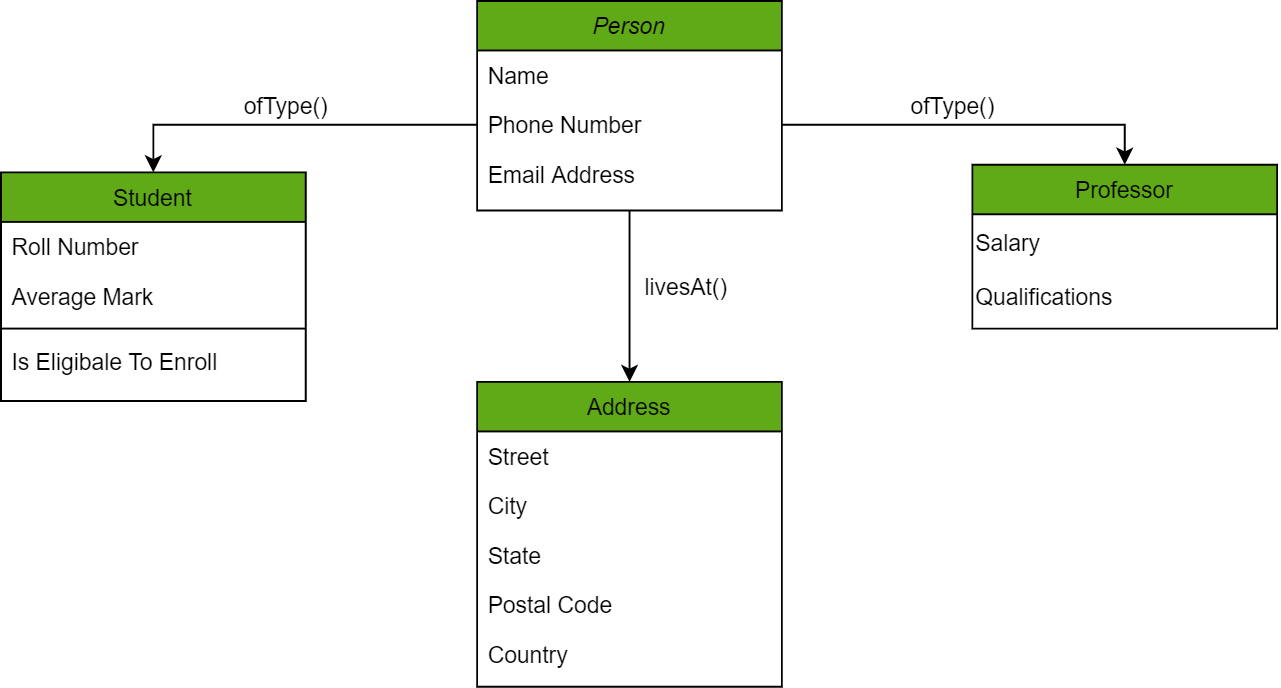
Object-Oriented Example
In the chart above, we have different objects linked to one another using methods; one can get the address of the Person (represented by the Person Object) using the livesAt() method. Furthermore, these objects have attributes which are in fact the data elements that need to be defined in the database.
An example of such a model is the Berkeley DB software library which uses the same conceptual background to deliver quick and highly efficient responses to database queries from the embedded database.
Relational Databases
Considered the most mature of all databases, these databases lead in the production line along with their management systems. In this database, every piece of information has a relationship with every other piece of information. This is on account of every data value in the database having a unique identity in the form of a record.
Note that all data is tabulated in this model. Therefore, every row of data in the database is linked with another row using a primary key. Similarly, every table is linked with another table using a foreign key.
Refer to the diagram below and notice how the concept of ‘Keys’ is used to link two tables.
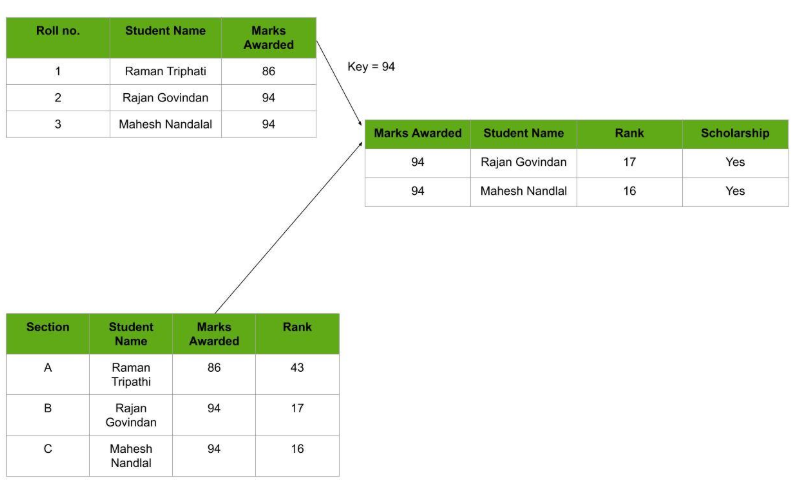
Relational Database Example
Due to this introduction of tables to organize data, it has become exceedingly popular. In consequence, they are widely integrated into Web-Ap interfaces to serve as ideal repositories for user data. What makes it further interesting is the ease in mastering it, since the language used to interact with the database is simple (SQL in this case) and easy to comprehend.
It is also worth being aware of the fact that in Relational databases, scaling and traversing through data is quite a light-weighted task in comparison to Hierarchical Databases.
Cloud Databases
A cloud database is used where data requires a virtual environment for storing and executing over the cloud platforms and there are so many cloud computing services for accessing the data from the databases (like SaaS, Paas, etc).
There are some names of cloud platforms are-
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- Microsoft Azure
- ScienceSoft, etc.
Centralized Databases
A centralized database is basically a type of database that is stored, located as well as maintained at a single location and it is more secure when the user wants to fetch the data from the Centralized Database.
Advantages
- Data Security
- Reduced Redundancy
- Consistency
Disadvantages
- The size of the centralized database is large which increases the response and retrieval time.
- It is not easy to modify, delete and update.
Personal Databases
Collecting and Storing the data on its own System and this type of databases is basically designed for the single user.
Advantages
- It is easy to handle
- It occupies less space
Operational Databases
It is used for creating, updating, and deleting the database in real-time and it is basically designed for executing and handling the daily data operation in organizations and businesses purposes.
Advantages
- easy to fetch.
- Structured data
- Real-time processing
NoSQL Databases
A NoSQL originally referring to non SQL or non-relational is a database that provides a mechanism for storage and retrieval of data. This data is modeled in means other than the tabular relations used in relational databases.
A NoSQL database includes simplicity of design, simpler horizontal scaling to clusters of machines, and finer control over availability. The data structures used by NoSQL databases are different from those used by default in relational databases which makes some operations faster in NoSQL. The suitability of a given NoSQL database depends on the problem it should solve. Data structures used by NoSQL databases are sometimes also viewed as more flexible than relational database tables.
MongoDB falls in the category of NoSQL document-based database.
Advantages of NoSQL
There are many advantages of working with NoSQL databases such as MongoDB and Cassandra. The main advantages are high scalability and high availability.
Disadvantages of NoSQL
NoSQL has the following disadvantages.
- NoSQL is an open-source database.
- GUI is not available
- Backup is a weak point for some NoSQL databases like MongoDB.
- Large document size.
These are but a few types of database structures which represent the fundamental concepts extensively used in the industry. However, as mentioned earlier, clients tend to focus on creating databases which would suit their own needs; to store data in a schema which showcases a variable functionality based on its blueprint. Hence, the scope for developme
Introduction of DBMS (Database Management System)
A database is a collection of interrelated data that helps in the efficient retrieval, insertion, and deletion of data from the database and organizes the data in the form of tables, views, schemas, reports, etc. For Example, a university database organizes the data about students, faculty, admin staff, etc. which helps in the efficient retrieval, insertion, and deletion of data from it.
What is DBMS?
A Database Management System (DBMS) is a software system that is designed to manage and organize data in a structured manner. It allows users to create, modify, and query a database, as well as manage the security and access controls for that database. DBMS provides an environment to store and retrieve data in convenient and efficient manner.
Key Features of DBMS
- Data modeling: A DBMS provides tools for creating and modifying data models, which define the structure and relationships of the data in a database.
- Data storage and retrieval: A DBMS is responsible for storing and retrieving data from the database, and can provide various methods for searching and querying the data.
- Concurrency control: A DBMS provides mechanisms for controlling concurrent access to the database, to ensure that multiple users can access the data without conflicting with each other.
- Data integrity and security: A DBMS provides tools for enforcing data integrity and security constraints, such as constraints on the values of data and access controls that restrict who can access the data.
- Backup and recovery: A DBMS provides mechanisms for backing up and recovering the data in the event of a system failure.
- DBMS can be classified into two types: Relational Database Management System (RDBMS) and Non-Relational Database Management System (NoSQL or Non-SQL)
- RDBMS: Data is organized in the form of tables and each table has a set of rows and columns. The data are related to each other through primary and foreign keys.
- NoSQL: Data is organized in the form of key-value pairs, documents, graphs, or column-based. These are designed to handle large-scale, high-performance scenarios.
Types of DBMS
- Relational Database Management System (RDBMS): Data is organized into tables (relations) with rows and columns, and the relationships between the data are managed through primary and foreign keys. SQL (Structured Query Language) is used to query and manipulate the data.
- NoSQL DBMS: Designed for high-performance scenarios and large-scale data, NoSQL databases store data in various non-relational formats such as key-value pairs, documents, graphs, or columns.
- Object-Oriented DBMS (OODBMS): Stores data as objects, similar to those used in object-oriented programming, allowing for complex data representations and relationships
Database Languages
- Data Definition Language
- Data Manipulation Language
- Data Control Language
- Transactional Control Language
Data Definition Language (DDL)
DDL is the short name for Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database.
- CREATE: to create a database and its objects like (table, index, views, store procedure, function, and triggers)
- ALTER: alters the structure of the existing database
- DROP: delete objects from the database
- TRUNCATE: remove all records from a table, including all spaces allocated for the records are removed
- COMMENT: add comments to the data dictionary
- RENAME: rename an object
Data Manipulation Language (DML)
DML is the short name for Data Manipulation Language which deals with data manipulation and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE, etc., and it is used to store, modify, retrieve, delete and update data in a database. Data query language(DQL) is the subset of “Data Manipulation Language”. The most common command of DQL is SELECT statement. SELECT statement help on retrieving the data from the table without changing anything in the table.
- SELECT: retrieve data from a database
- INSERT: insert data into a table
- UPDATE: updates existing data within a table
- DELETE: Delete all records from a database table
- MERGE: UPSERT operation (insert or update)
- CALL: call a PL/SQL or Java subprogram
- EXPLAIN PLAN: interpretation of the data access path
- LOCK TABLE: concurrency Control
Data Control Language (DCL)
DCL is short for Data Control Language which acts as an access specifier to the database.(basically to grant and revoke permissions to users in the database
- GRANT: grant permissions to the user for running DML(SELECT, INSERT, DELETE,…) commands on the table
- REVOKE: revoke permissions to the user for running DML(SELECT, INSERT, DELETE,…) command on the specified table
Transactional Control Language (TCL)
TCL is short for Transactional Control Language which acts as an manager for all types of transactional data and all transactions. Some of the command of TCL are
- Roll Back: Used to cancel or Undo changes made in the database
- Commit: It is used to apply or save changes in the database
- Save Point: It is used to save the data on the temporary basis in the database
Data Query Language (DQL)
Data query language(DQL) is the subset of “Data Manipulation Language”. The most common command of DQL is 1the SELECT statement. SELECT statement helps us in retrieving the data from the table without changing anything or modifying the table. DQL is very important for retrieval of essential data from a database.
Paradigm Shift from File System to DBMS
File System manages data using files on a hard disk. Users are allowed to create, delete, and update the files according to their requirements. Let us consider the example of file-based University Management System. Data of students is available to their respective Departments, Academics Section, Result Section, Accounts Section, Hostel Office, etc. Some of the data is common for all sections like Roll No, Name, Father Name, Address, and Phone number of students but some data is available to a particular section only like Hostel allotment number which is a part of the hostel office. Let us discuss the issues with this system:
- Redundancy of data: Data is said to be redundant if the same data is copied at many places. If a student wants to change their Phone number, he or she has to get it updated in various sections. Similarly, old records must be deleted from all sections representing that student.
- Inconsistency of Data: Data is said to be inconsistent if multiple copies of the same data do not match each other. If the Phone number is different in Accounts Section and Academics Section, it will be inconsistent. Inconsistency may be because of typing errors or not updating all copies of the same data.
- Difficult Data Access: A user should know the exact location of the file to access data, so the process is very cumbersome and tedious. If the user wants to search the student hostel allotment number of a student from 10000 unsorted students’ records, how difficult it can be.
- Unauthorized Access: File Systems may lead to unauthorized access to data. If a student gets access to a file having his marks, he can change it in an unauthorized way.
- No Concurrent Access: The access of the same data by multiple users at the same time is known as concurrency. The file system does not allow concurrency as data can be accessed by only one user at a time.
- No Backup and Recovery: The file system does not incorporate any backup and recovery of data if a file is lost or corrupted.
These are the main reasons which made a shift from file system to DBMS. Also See, Advantages of DBMS over File System
Advantages of DBMS
- Data organization: A DBMS allows for the organization and storage of data in a structured manner, making it easy to retrieve and query the data as needed.
- Data integrity: A DBMS provides mechanisms for enforcing data integrity constraints, such as constraints on the values of data and access controls that restrict who can access the data.
- Concurrent access: A DBMS provides mechanisms for controlling concurrent access to the database, to ensure that multiple users can access the data without conflicting with each other.
- Data security: A DBMS provides tools for managing the security of the data, such as controlling access to the data and encrypting sensitive data.
- Backup and recovery: A DBMS provides mechanisms for backing up and recovering the data in the event of a system failure.
- Data sharing: A DBMS allows multiple users to access and share the same data, which can be useful in a collaborative work environment.
Disadvantages of DBMS
- Complexity: DBMS can be complex to set up and maintain, requiring specialized knowledge and skills.
- Performance overhead: The use of a DBMS can add overhead to the performance of an application, especially in cases where high levels of concurrency are required.
- Scalability: The use of a DBMS can limit the scalability of an application, since it requires the use of locking and other synchronization mechanisms to ensure data consistency.
- Cost: The cost of purchasing, maintaining and upgrading a DBMS can be high, especially for large or complex systems.
- Limited Use Cases: Not all use cases are suitable for a DBMS, some solutions don’t need high reliability, consistency or security and may be better served by other types of data storage.
Applications of DBMS
- Enterprise Information: Sales, accounting, human resources, Manufacturing, online retailers.
- Banking and Finance Sector: Banks maintaining the customer details, accounts, loans, banking transactions, credit card transactions. Finance: Storing the information about sales and holdings, purchasing of financial stocks and bonds.
- University: Maintaining the information about student course enrolled information, student grades, staff roles.
- Airlines: Reservations and schedules.
- Telecommunications: Prepaid, postpaid bills maintance.
Conclusion
A Database Management System (DBMS) is an essential tool for efficiently managing, organizing, and retrieving large volumes of data across various industries. Its ability to handle data securely, ensure integrity, support concurrent access, and provide backup and recovery options makes it indispensable for modern data-driven applications. While DBMSs come with complexities and costs, their benefits in terms of data management and security far outweigh the challenges, making them a crucial component in any data-centric environment
History of DBMS
Data is a collection of facts and figures. The data collection was increasing day to day and they needed to be stored in a device or a safer software. Charles Bachman was the first person to develop the Integrated Data Store (IDS) which was based on a network data model for which he was inaugurated with the Turing Award (The most prestigious award which is equivalent to the Nobel prize in the field of Computer Science.). It was developed in the early 1960s. In the late 1960s, IBM (International Business Machines Corporation) developed the Integrated Management Systems which is the standard database system used to date in many places. It was developed based on the hierarchical database model. It was during the year 1970 that the
relational database model
was developed by Edgar Codd. Many of the database models we use today are relational-based. It was considered the standardized database model from then. The relational model was still in use by many people in the market. Later during the same decade (1980’s), IBM developed the
Structured Query Language (SQL)
as a part of the R project. It was declared as a standard language for the queries by ISO and ANSI. The Transaction Management System for processing transactions was also developed by James Gray for which he was felicitated the Turing Award. Further, there were many other models with rich features like complex queries, datatypes to insert images, and many others. The Internet Age has perhaps influenced the data models much more. Data models were developed using object-oriented programming features, embedding with scripting languages like
Hyper Text Markup Language (HTML)
for queries. With humongous data being available online, DBMS is gaining more significance day by day.
Techniques for data storage and processing have evolved over the years:
- 1950s and early 1960s: Magnetic tapes were developed for data storage. Data processing tasks such as payroll were automated, with data stored on tapes. Processing of data consisted of reading data from one or more tapes and writing data to a new tape. Data could also be input from punched card decks, and output to printers. For example, salary raises were processed by entering the raises on punched cards and reading the punched card deck in synchronization with a tape containing the master salary details. The records had to be in the same sorted order. The salary raises would be added to the salary read from the master tape, and written to a new tape; the new tape would become the new master tape. Tapes (and card decks) could be read only sequentially, and data sizes were much larger than main memory; thus, data processing programs were forced to process data in a particular order, by reading and merging data from tapes and card decks.
- Late 1960s and 1970s: Widespread use of hard disks in the late 1960s changed the scenario for data processing greatly, since hard disks allowed direct access to data. The position of data on disk was immaterial, since any location on disk could be accessed in just tens of milliseconds. Data were thus freed from the tyranny of sequentiality. With disks, network and hierarchical databases could be created that allowed data structures such as lists and trees to be stored on disk. Programmers could construct and manipulate these data structures. A landmark paper by Codd [1970] defined the relational model and nonprocedural ways of querying data in the relational model, and relational databases were born. The simplicity of the relational model and the possibility of hiding implementation details completely from the programmer were enticing indeed. Codd later won the prestigious Association of Computing Machinery Turing Award for his work.
- 1980s: Although academically interesting, the relational model was not used in practice initially, because of its perceived performance disadvantages; relational databases could not match the performance of existing network and hierarchical databases. That changed with System R, a groundbreaking project at IBM Research that developed techniques for the construction of an efficient relational database system. Excellent overviews of System R are provided by Astrahan et al. [1976] and Chamberlin et al. [1981]. The fully functional System R prototype led to IBM’s first relational database product, SQL/DS. At the same time, the Ingres system was being developed at the University of California at Berkeley. It led to a commercial product of the same name. Initial commercial relational database systems, such as IBM DB2, Oracle, Ingres, and DEC Rdb, played a major role in advancing techniques for efficient processing of declarative queries. By the early 1980s, relational databases had become competitive with network and hierarchical database systems even in the area of performance. Relational databases were so easy to use that they eventually replaced network and hierarchical databases; programmers using such databases were forced to deal with many low-level implementation details, and had to code their queries in a procedural fashion. Most importantly, they had to keep efficiency in mind when designing their programs, which involved a lot of effort. In contrast, in a relational database, almost all these low-level tasks are carried out automatically by the database, leaving the programmer free to work at a logical level. Since attaining dominance in the 1980s, the relational model has reigned supreme among data models. The 1980s also saw much research on parallel and distributed databases, as well as initial work on object-oriented databases.
- Early 1990s: The SQL language was designed primarily for decision support applications, which are query-intensive, yet the mainstay of databases in the 1980s was transaction-processing applications, which are update-intensive. Decision support and querying re-emerged as a major application area for databases. Tools for analyzing large amounts of data saw large growths in usage. Many database vendors introduced parallel database products in this period. Database vendors also began to add object-relational support to their databases.
- 1990s: The major event of the 1990s was the explosive growth of the World Wide Web. Databases were deployed much more extensively than ever before. Database systems now had to support very high transaction-processing rates, as well as very high reliability and 24 × 7 availability (availability 24 hours a day, 7 days a week, meaning no downtime for scheduled maintenance activities). Database systems also had to support Web interfaces to data.
- 2000s: The first half of the 2000s saw the emerging of XML and the associated query language XQuery as a new database technology. Although XML is widely used for data exchange, as well as for storing certain complex data types, relational databases still form the core of a vast majority of large-scale database applications. In this time period we have also witnessed the growth in “autonomic-computing/auto-admin” techniques for minimizing system administration effort. This period also saw a significant growth in use of open-source database systems, particularly PostgreSQL and MySQL. The latter part of the decade has seen growth in specialized databases for data analysis, in particular column-stores, which in effect store each column of a table as a separate array, and highly parallel database systems designed for analysis of very large data sets. Several novel distributed data-storage systems have been built to handle the data management requirements of very large Web sites such as Amazon, Facebook, Google, Microsoft and Yahoo!, and some of these are now offered as Web services that can be used by application developers. There has also been substantial work on management and analysis of streaming data, such as stock-market ticker data or computer network monitoring data. Data-mining techniques are now widely deployed; example applications include Web-based product-recommendation systems and automatic placement of relevant advertisements on Web pages.
Advantages of Database Management System
Database Management System (DBMS) is a collection of interrelated data and a set of software tools/programs that access, process, and manipulate data. It allows access, retrieval, and use of that data by considering appropriate security measures. The Database Management system (DBMS) is really useful for better data integration and security.
.png)
Advantages of DBMS
Advantages of Database Management System
The advantages of database management systems are:
- Data Security: The more accessible and usable the database, the more it is prone to security issues. As the number of users increases, the data transferring or data sharing rate also increases thus increasing the risk of data security. It is widely used in the corporate world where companies invest large amounts of money, time, and effort to ensure data is secure and used properly. A Database Management System (DBMS) provides a better platform for data privacy and security policies thus, helping companies to improve Data Security.
- Data integration: Due to the Database Management System we have access to well-managed and synchronized forms of data thus it makes data handling very easy and gives an integrated view of how a particular organization is working and also helps to keep track of how one segment of the company affects another segment.
- Data abstraction: The major purpose of a database system is to provide users with an abstract view of the data. Since many complex algorithms are used by the developers to increase the efficiency of databases that are being hidden by the users through various data abstraction levels to allow users to easily interact with the system.
- Reduction in data Redundancy: When working with a structured database, DBMS provides the feature to prevent the input of duplicate items in the database. for e.g. – If there are two same students in different rows, then one of the duplicate data will be deleted.
- Data sharing: A DBMS provides a platform for sharing data across multiple applications and users, which can increase productivity and collaboration.
- Data consistency and accuracy: DBMS ensures that data is consistent and accurate by enforcing data integrity constraints and preventing data duplication. This helps to eliminate data discrepancies and errors that can occur when data is stored and managed manually.
- Data organization: A DBMS provides a systematic approach to organizing data in a structured way, which makes it easier to retrieve and manage data efficiently.
- Efficient data access and retrieval: DBMS allows for efficient data access and retrieval by providing indexing and query optimization techniques that speed up data retrieval. This reduces the time required to process large volumes of data and increases the overall performance of the system.
- Concurrency and maintained Atomicity: That means, if some operation is performed on one particular table of the database, then the change must be reflected for the entire database. The DBMS allows concurrent access to multiple users by using the synchronization technique.
- Scalability and flexibility: DBMS is highly scalable and can easily accommodate changes in data volumes and user requirements. DBMS can easily handle large volumes of data, and can scale up or down depending on the needs of the organization. It provides flexibility in data storage, retrieval, and manipulation, allowing users to easily modify the structure and content of the database as needed.
Advantages of Database Management System over Traditional File System
- Better Data Security: DBMS provides a centralized approach to data management that ensures data integrity and security. To prevent illegal access, alteration, or theft, database management systems (DBMS) include a number of security features, including encryption, authentication, and authorization. Sensitive data is safeguarded against both internal and external attacks thanks to this.
- Reduced Data Redundancy: DBMS eliminates data redundancy by storing data in a structured way. It allows sharing data across different applications and users, reducing the need for duplicating data. By keeping data centrally and offering methods for sharing and reusing it, database management systems (DBMS) remove data redundancy. As a result, less data storage is needed, and data consistency is increased.
- Improved Data Consistency: DBMS allows defining constraints and rules to ensure that data is consistent and accurate. DBMS ensures data consistency by enforcing data validation rules and constraints. This ensures that data is accurate and consistent across different applications and users.
- Improved Data Access and Availability: DBMS provides efficient data access and retrieval mechanisms that enable quick and easy data access. It allows multiple users to access the data simultaneously, ensuring data availability.
- Improved Data Sharing: DBMS provides a platform for sharing data across different applications and users. It allows sharing data between different departments and systems within an organization, improving collaboration and decision-making. Database Management Systems prevent conflicts and data loss by enabling numerous people to view and edit the same data at once. This promotes teamwork and enhances data uniformity throughout the company.
- Improved Data Integration: DBMS allows integrating data from different sources, providing a comprehensive view of the data. It enables data integration from different systems and platforms, improving the quality of data analysis. To avoid data mistakes and inconsistencies, database management systems (DBMSs) apply data integrity requirements including referential integrity, entity integrity, and domain integrity. This guarantees the consistency, accuracy, and completeness of the data.
- Improved Data Backup and Recovery: DBMS provides backup and recovery mechanisms that ensure data is not lost in case of a system failure. It allows restoring data to a specific point in time, ensuring data consistency. Database management systems (DBMS) offer backup and recovery features that let businesses swiftly and effectively restore lost or damaged data. This guarantees business continuity and lowers the chance of data loss.
- Data independence: By separating the logical and physical views of data, database management systems (DBMS) enable users to work with data without being aware of its exact location or structure. This offers adaptability and lowers the possibility of data damage as a result of modifications to the underlying hardware or software.
Conclusion
Overall, Database management System offers several advantages over traditional file-based systems. It ensures data integrity, security, and consistency, reduces data redundancy, and improves data access, sharing, and integration. These benefits make DBMS an essential tool for managing and processing data in modern organizations.
Application of DBMS
The efficient and safe management, saving and retrieval of data is made possible by the Database Management Systems. They provide strong solutions for the data management demands and are the foundation of the numerous applications used in a variety of the sectors. Recognizing the uses of DBMSs aids in understanding their significance in contemporary company operations and technology.
What is DBMS?
A Database Management System (DBMS) makes easier to create, maintain and work with the databases. It acts as the channel between end users and the database enabling the functions including administration, retrieval, updating and storing of data. By structuring data into the organized formats and controlling concurrent access the database management systems (DBMSs) contribute to the efficient handling, security and integrity of data.
There are different fields where a database management system is utilized. Following are a few applications that utilize the information base administration framework.
.png)
Applications of DBMS
1. Railway Reservation System
In the rail route reservation framework, the information base is needed to store the record or information of ticket appointments, status of train’s appearance, and flight. Additionally, if trains get late, individuals become acquainted with it through the information base update.
2. Library Management System
There are many books in the library so; it is difficult to store the record of the relative multitude of books in a register or duplicate. Along these lines, the data set administration framework (DBMS) is utilized to keep up all the data identified with the name of the book, issue date, accessibility of the book, and its writer.
3. Banking
Database the executive’s framework is utilized to store the exchange data of the client in the information base.
4. Education Sector
Presently, assessments are led online by numerous schools and colleges. They deal with all assessment information through the data set administration framework (DBMS). In spite of that understudy’s enlistments subtleties, grades, courses, expense, participation, results, and so forth all the data is put away in the information base.
5. Credit card exchanges
The database Management framework is utilized for buying on charge cards and age of month to month proclamations.
6. Social Media Sites
We all utilization of online media sites to associate with companions and to impart our perspectives to the world. Every day, many people group pursue these online media accounts like Pinterest, Facebook, Twitter, and Google in addition to. By the utilization of the data set administration framework, all the data of clients are put away in the information base and, we become ready to interface with others.
7. Broadcast communications
Without DBMS any media transmission organization can’t think. The Database the executive’s framework is fundamental for these organizations to store the call subtleties and month to month postpaid bills in the information base.
8. Accounting and Finance
The information base administration framework is utilized for putting away data about deals, holding and acquisition of monetary instruments, for example, stocks and bonds in a data set.
9. E-Commerce Websites
These days, web-based shopping has become a major pattern. Nobody needs to visit the shop and burn through their time. Everybody needs to shop through web based shopping sites, (for example, Amazon, Flipkart, Snapdeal) from home. So all the items are sold and added uniquely with the assistance of the information base administration framework (DBMS). Receipt charges, installments, buy data these are finished with the assistance of DBMS.
10. Human Resource Management
Big firms or organizations have numerous specialists or representatives working under them. They store data about worker’s compensation, assessment, and work with the assistance of an information base administration framework (DBMS).
11. Manufacturing
Manufacturing organizations make various kinds of items and deal them consistently. To keep the data about their items like bills, acquisition of the item, amount, inventory network the executives, information base administration framework (DBMS) is utilized.
12. Airline Reservation System
This framework is equivalent to the railroad reservation framework. This framework additionally utilizes an information base administration framework to store the records of flight takeoff, appearance, and defer status.
13. Healthcare System
DBMS is used in healthcare to manage patient data, medical records, and billing information.
14. Security
DBMS provides security features to ensure that only authorized users have access to the data.
15. Telecommunication
Database Management Systems (DBMS) are essential to the telecommunications industry because they manage enormous volumes of data on billing, customer information, and network optimization.
Conclusion
In Conclusion, database management systems, or DBMS, are essential to effective, safe, and well-organized data management. They offer multiple user access, enable scalability, and guarantee integrity. Data recovery, decision support, and web-based platforms are just a few of the uses for database management systems (DBMS) that are essential to contemporary information systems and satisfy a wide range of business objectives.
Need for DBMS
A Data Base Management System is a system software for easy, efficient and reliable data processing and management. It can be used for:
- Creation of a database.
- Retrieval of information from the database.
- Updating the database.
- Managing a database.
- Multiple User Interface
- Data scalability, expandability and flexibility: We can change schema of the database, all schema will be updated according to it.
- Overall the time for developing an application is reduced.
- Security: Simplifies data storage as it is possible to assign security permissions allowing restricted access to data.
Data organization: DBMS allow users to organize large amounts of data in a structured and systematic way. Data is organized into tables, fields, and records, making it easy to manage, store, and retrieve information.
Data scalability: DBMS are designed to handle large amounts of data and are scalable to meet the growing needs of organizations. As organizations grow, DBMS can scale up to handle increasing amounts of data and user traffic.
we will discuss the need for a DBMS in detail, covering the following points:
1.Data Organization and Management
2.Data Security and Privacy
3.Data Integrity and Consistency
4.Concurrent Data Access
5.Data Analysis and Reporting
6.Scalability and Flexibility
7.Cost-Effectiveness
1. Data Organization and Management:
One of the primary needs for a DBMS is data organization and management. DBMSs allow data to be stored in a structured manner, which helps in easier retrieval and analysis. A well-designed database schema enables faster access to information, reducing the time required to find relevant data. A DBMS also provides features like indexing and searching, which make it easier to locate specific data within the database. This allows organizations to manage their data more efficiently and effectively.
2. Data Security and Privacy:
DBMSs provide a robust security framework that ensures the confidentiality, integrity, and availability of data. They offer authentication and authorization features that control access to the database. DBMSs also provide encryption capabilities to protect sensitive data from unauthorized access. Moreover, DBMSs comply with various data privacy regulations such as the GDPR, HIPAA, and CCPA, ensuring that organizations can store and manage their data in compliance with legal requirements.
3. Data Integrity and Consistency:
Data integrity and consistency are crucial for any database. DBMSs provide mechanisms that ensure the accuracy and consistency of data. These mechanisms include constraints, triggers, and stored procedures that enforce data integrity rules. DBMSs also provide features like transactions that ensure that data changes are atomic, consistent, isolated, and durable (ACID).
4. Concurrent Data Access:
A DBMS provides a concurrent access mechanism that allows multiple users to access the same data simultaneously. This is especially important for organizations that require real-time data access. DBMSs use locking mechanisms to ensure that multiple users can access the same data without causing conflicts or data corruption.
5. Data Analysis and Reporting:
DBMSs provide tools that enable data analysis and reporting. These tools allow organizations to extract useful insights from their data, enabling better decision-making. DBMSs support various data analysis techniques such as OLAP, data mining, and machine learning. Moreover, DBMSs provide features like data visualization and reporting, which enable organizations to present their data in a visually appealing and understandable way.
6. Scalability and Flexibility:
DBMSs provide scalability and flexibility, enabling organizations to handle increasing amounts of data. DBMSs can be scaled horizontally by adding more servers or vertically by increasing the capacity of existing servers. This makes it easier for organizations to handle large amounts of data without compromising performance. Moreover, DBMSs provide flexibility in terms of data modeling, enabling organizations to adapt their databases to changing business requirements.
7. Cost-Effectiveness:
DBMSs are cost-effective compared to traditional file-based systems. They reduce storage costs by eliminating redundancy and optimizing data storage. They also reduce development costs by providing tools for database design, maintenance, and administration. Moreover, DBMSs reduce operational costs by automating routine tasks and providing self-tuning capabilities.
DBMS ( Database Management System)
Database Management System is basically software that manages the collection of related data. It is used for storing data and retrieving the data effectively when it is needed. It also provides proper security measures for protecting the data from unauthorized access. In Database Management System the data can be fetched by SQL queries and relational algebra. It also provides mechanisms for data recovery and data backup.
Example:
Oracle, MySQL, MS SQL server.

DBMS
Difference Between File System and DBMS
|
Basics |
File System |
DBMS |
|---|---|---|
|
Structure |
The file system is a way of arranging the files in a storage medium within a computer. |
DBMS is software for managing the database. |
|
Data Redundancy |
Redundant data can be present in a file system. |
In DBMS there is no redundant data. |
|
Backup and Recovery |
It doesn’t provide Inbuilt mechanism for backup and recovery of data if it is lost. |
It provides in house tools for backup and recovery of data even if it is lost. |
|
Query processing |
There is no efficient query processing in the file system. |
Efficient query processing is there in DBMS. |
|
Consistency |
There is less data consistency in the file system. |
There is more data consistency because of the process of normalization. |
|
Complexity |
It is less complex as compared to DBMS. |
It has more complexity in handling as compared to the file system. |
|
Security Constraints |
File systems provide less security in comparison to DBMS. |
DBMS has more security mechanisms as compared to file systems. |
|
Cost |
It is less expensive than DBMS. |
It has a comparatively higher cost than a file system. |
|
Data Independence |
There is no data independence. |
In DBMS data independence exists, mainly of two types: 1) Logical Data Independence. 2)Physical Data Independence. |
|
User Access |
Only one user can access data at a time. |
Multiple users can access data at a time. |
|
Meaning |
The users are not required to write procedures. |
The user has to write procedures for managing databases |
|
Sharing |
Data is distributed in many files. So, it is not easy to share data. |
Due to centralized nature data sharing is easy |
|
Data Abstraction |
It give details of storage and representation of data |
It hides the internal details of Database |
|
Integrity Constraints |
Integrity Constraints are difficult to implement |
Integrity constraints are easy to implement |
| Attributes | To access data in a file , user requires attributes such as file name, file location. | No such attributes are required. |
|
Example |
Cobol, C++ |
Oracle, SQL Server |
The main difference between a file system and a DBMS (Database Management System) is the way they organize and manage data.
- File systems are used to manage files and directories, and provide basic operations for creating, deleting, renaming, and accessing files. They typically store data in a hierarchical structure, where files are organized in directories and subdirectories. File systems are simple and efficient, but they lack the ability to manage complex data relationships and ensure data consistency.
- On the other hand, DBMS is a software system designed to manage large amounts of structured data, and provide advanced operations for storing, retrieving, and manipulating data. DBMS provides a centralized and organized way of storing data, which can be accessed and modified by multiple users or applications. DBMS offers advanced features like data validation, indexing, transactions, concurrency control, and backup and recovery mechanisms. DBMS ensures data consistency, accuracy, and integrity by enforcing data constraints, such as primary keys, foreign keys, and data types.
In summary, file systems are suitable for managing small amounts of unstructured data, while DBMS is designed for managing large amounts of structured data, and offers more advanced features for ensuring data integrity, security, and performance.
Conclusion
On balance, a File System focuses more on organizing, creating, storing, retrieving, renaming and deleting files at a storage device and mainly deals with fundamental levels of data operations. It is user-friendly and convenient for dealing with various files and directories but does not support complex data handling. In contrast, a DBMS is intended for comprehensive data storage, providing organization, efficient data access, and reliable information integrity. DBMS is appropriate for complex cases of data management, with many records that require storage, searching and updating.
v
Non-Relational Databases and Their Types
In the area of database management, the data is arranged in two ways which are Relational Databases (SQL) and Non-Relational Databases (NoSQL). While relational databases organize data into structured tables, non-relational databases use various flexible data models like key-value pairs, documents, graphs, and wide–column stores.
Here, we will learn about non-relational database meaning and check non-relational database examples. But to understand non-relational databases, or “NoSQL” databases, we first need to look at relational databases.
Relational Database (SQL)
- A relational database stores data in a table composed of rows and columns. The table represents an object or entity, such as users, customers, orders, etc.
- The column represents the type of data that can be stored in the respective column.
- Relational Databases allow users to establish a connection between tables using keys for flexible data flow and querying.
- SQL was specifically designed to work with tabular data. These are often categorized as structured data.
- This is because there can only be a single schema or structure for the data within a relational database.
- SQL is a declarative language, which means that you describe in SQL syntax the desired result you wish from the query.
Key features of relational database

Key Features of Relational Databases
- Relational data models are similar to an Excel spreadsheet, with related data stored in rows and columns in one table.
- SQL (Structured Query Language) is the most common way of interacting with relational database systems. Developers can use SQL queries to execute CRUD (Create, Read, Update, Delete) operations.
Non-Relational database (NoSQL)
- Non-relational databases different from relational databases because they do not store data in tabular form.
- Instead, non-relational databases are based on data structures like documents and graphs. NoSQL databases also come in a variety of types based on their data models.
- They offer scalability when dealing with large volumes of data and high load factors. They were designed when data was expected to be partitioned across multiple machines to scale, in contrast to relational databases, which assumed the data would stay on a single machine.
The benefits of a non-relational database
- Scalability: Non-relational databases like MongoDB and Cassandra are designed to horizontally scale across clusters of cheap commodity hardware, offering seamless scalability as data volumes and user loads increase.
- Flexibility in Data Models: Unlike rigid table-based structures in relational databases, non-relational databases support flexible data models like document stores (e.g., JSON in MongoDB), key-value pairs (e.g., Redis), and wide-column stores (e.g., Cassandra), making it easier to store and manage unstructured or semi-structured data.
- Performance: Non-relational databases are optimized for specific use cases such as real-time data ingestion, high-speed transactions, and rapid access to large volumes of data. They often outperform relational databases in these scenarios due to their distributed architecture and optimized data storage formats.
- Schemaless Design: Non-relational databases typically do not enforce a rigid schema, allowing developers to evolve the data structure over time without downtime or complex migrations. This advantage is particularly beneficial in agile development environments and for handling diverse and unpredictable data types.
- High Availability and Fault Tolerance: Many non-relational databases are designed with built-in replication and automatic failover capabilities, ensuring high availability and data redundancy. This makes them suitable for mission-critical applications where continuous uptime is essential.
- Cost-Effectiveness: By using commodity hardware and open-source software, non-relational databases often provide a more cost-effective solution compared to traditional relational databases, especially at scale.
What do NoSQL databases have in common?
- Non-Relational Structure: NoSQL databases store data in flexible formats like key-value pairs, documents, or graphs, allowing for easier adaptation to changing data needs.
- Scalability: It is Designed for horizontal scaling across multiple servers, enabling efficient handling of large data volumes and high transaction rates.
- High Performance: It is Highly Optimized for specific query types and workloads, prioritizing low latency and high throughput.
- Flexibility in Data Models: It Supports various data structures (e.g., documents, columns, graphs) to fit diverse application requirements without rigid schemas.
- Eventual Consistency: It Emphasizes availability and partition tolerance over strict immediate consistency across distributed nodes.
- Horizontal Partitioning: It Uses sharding to distribute data across multiple nodes, improving performance and managing large datasets efficiently.
Non-Relational Database Types
There are four main types of non-relational databases:
- key/value
- graph
- column
- document

Non Relational Databases
1. Key/Value Database

Key/ Value Database
Key-value databasesuse a straightforward schema: a unique key is paired with a collection of values, where the values can be anything from a string to a large binary object. One of the benefits of using this structure in a database is that you don’t have to worry about complex queries. Because the system knows where the data is stored, it only sends a request to that particular server.
Example of Key/Value Database
|
Key |
Value |
|---|---|
|
Name |
John Snow |
|
Age |
23 |
2. Graph Database

Graph Database
Graph database is another type of non-relational database. A popular example of a graph database is Neo4J. This database stores information as a collection of nodes and edges, where the edges represent the relationships between the nodes.
3. Column Oriented Database

Wide Column
A column-oriented or wide-column non-relational database is primarily designed for analytics. Cassandra is a commonly used column-oriented database.
The advantage of column-oriented/row-oriented databases is that column-oriented databases return data in columns, making the query much more performant as it will not return many irrelevant fields that are not required for the query being serviced.
The primary key in a column-oriented database is the data or value, which is then mapped to row keys. This is the inverse, or opposite, of how the primary key works in a relational database.
Example of Column Oriented Database

4. Document Database

Document databases, such as MongoDB, store data in a single document, which can have different shapes within the single collection or table that stores the documents. It provides a clear means of capturing relationships using sub-documents and embedded arrays within a single document.
Example of Document Database

Non-Relational Database Management Systems
Some of the popular Non-Relational Database Management Systems are:
- MongoDB
- Apache Cassandra
- Redis
- Couchbase
- Apache HBase
- Neo4j
- Riak
- Aerospike
- OrientDB
- ArangoDB
These are some Non-relational database names, that you might hear in the market. Decide on which Non-relational database software is best for your work, and master that.
Relational vs Non-Relational Database
Here’s a comparison of Relational and Non-Relational Databases in tabular format:
| Feature | Relational Database | Non-Relational Database |
|---|---|---|
| Data Structure | Tables with rows and columns | Various formats (document, key-value, columnar, graph) |
| Schema | Structured schema enforced by schemas | Flexible schema, often schema-less or dynamic |
| Query Language | SQL (Structured Query Language) | Query languages specific to the database type (e.g., JSON query languages, graph traversal languages) |
| ACID Compliance | ACID transactions | May vary; some offer ACID compliance, others eventual consistency |
| Scalability | Vertical and horizontal scaling options | Horizontal scaling typically easier and more flexible |
| Flexibility | Less flexible with rigid schema definitions | Highly flexible due to schema-less or dynamic schema |
| Performance | Excellent for complex queries and joins | Optimal for hierarchical data storage and retrieval |
| Examples | MySQL, PostgreSQL, SQL Server | MongoDB, Cassandra, Redis, DynamoDB |
Conclusion
In conclusion, the choice between relational and non-relational databases depends largely on the nature of the data and the requirements of the application. Relational databases excel in structured data environments where data integrity and complex querying are paramount. On the other hand, non-relational databases shine in scenarios demanding scalability, flexibility in data models, and high performance across distributed systems.
What is SQL?
Structured Query Language (SQL) is a specialized programming language for managing relational database data. It allows users to store, manipulate, and retrieve data efficiently in databases like MySQL, SQL Server, Oracle, and more.
In this article, we will learn about what is SQL? and check its characteristics, rules, uses, commands, etc.
Table of Content
- What is SQL?
- Components of a SQL System
- What are the characteristics of SQL?
- How SQL Works?
- SQL Rules
- What are SQL commands?
- Uses of SQL
- Why SQL?
- SQL Injection
- What is SQL Server?
What is SQL?
SQL stands for Structured Query Language. SQL is a computer language used to interact with relational database systems. SQL is a tool for organizing, managing, and retrieving archived data from a computer database.
When data needs to be retrieved from a database, SQL is used to make the request. The DBMS processes the SQL query retrieves the requested data and returns it to us. Rather, SQL statements describe how a collection of data should be organized or what data should be extracted or added to the database.
In common usage, SQL encompasses DDL and DML commands for CREATE, UPDATE, MODIFY, or other operations on database structure.
SQL History
- SQL was invented in 1970s and was first commercially distributed by Oracle.
- The original name was given by IBM as Structured English Query Language, abbreviated by the acronym SEQUEL.
Components of a SQL System
Some of the Key components of a SQL System are:
Databases
Databases are structured collections of data organized into tables, rows, and columns. They serve as repositories for storing information efficiently and provide a way to manage and access data.
Tables
Tables are the fundamental building blocks of a database, consisting of rows (records) and columns (attributes or fields). They ensure data integrity and consistency by defining the structure and relationships of the stored information.
Queries
Queries are SQL commands used to interact with databases. They enable users to retrieve, update, insert, or delete data from tables, allowing for efficient data manipulation and retrieval.
Constraints
Constraints are rules applied to tables to maintain data integrity. They define conditions that data must meet to be stored in the database, ensuring accuracy and consistency.
Stored Procedures
Stored procedures are pre-compiled SQL statements stored in the database. They can accept parameters, execute complex operations, and return results, enhancing efficiency, reusability, and security in database management.
Transactions
Transactions are groups of SQL statements that are executed as a single unit of work. They ensure data consistency and integrity by allowing for the rollback of changes if any part of the transaction fails.
Some other important components include:
- Data Types
- Indexes
- Views
- Security and Permissions
- Joins
What are the characteristics of SQL?
- SQL may be utilized by quite a number of users, which include people with very little programming experience.
- SQL is a non-procedural language.
- We can without difficulty create and replace databases in SQL. It isn’t a time-consuming process.
- SQL is primarily based totally on ANSI standards.
- SQL does now no longer have a continuation individual.
- SQL is entered into the SQL buffer on one or more lines.
- SQL makes use of a termination individual to execute instructions immediately. It makes use of features to carry out a few formatting.
- It uses functions to perform some formatting.
How SQL Works?
A server machine is used in the implementation of the structured query language (SQL), processing database queries and returning results. The following are some of the software elements that the SQL process goes through.
Parser
The parser begins by replacing some of the words in the SQL statement with unique symbols, a process known as tokenization. The statement is then examined for the following:
Correctness
The parser checks to see if the SQL statement complies with the rules, or SQL semantics, that guarantee the query statement’s accuracy. The parser, for instance, looks to see if the SQL command ends with a semicolon. The parser returns an error if the semi-colon is absent.
Authorization
The parser additionally confirms that the user executing the query has the required permissions to alter the relevant data.
Relational Engine
The relational engine, also known as the query processor, develops a strategy for efficiently retrieving, writing, or updating relevant data. For instance, it looks for queries that are similar to others, uses earlier data manipulation techniques, or develops a new one. Byte code, an intermediate-level representation of the SQL statement, is used to write the plan. To efficiently perform database searches and modifications, relational databases use byte code.
Storage Engine
The software element that interprets the byte code and executes the intended SQL statement is known as the storage engine, also known as the database engine. The data in the database files on the physical disc storage is read and stored. The storage engine delivers the outcome to the requesting application after completion.
SQL Rules
The rules for writing SQL queries are given below:
- A ‘;’ is used to end SQL statements.
- Statements may be split across lines, but keywords may not.
- Identifiers, operator names, and literals are separated by one or more spaces or other delimiters.
- A comma (,) separates parameters without a clause.
- A space separates a clause.
- Reserved words cannot be used as identifiers unless enclosed with double quotes.
- Identifiers can contain up to 30 characters.
- Identifiers must start with an alphabetic character.
- Characters and date literals must be enclosed within single quotes.
- Numeric literals can be represented by simple values.
- Comments may be enclosed between /* and */ symbols and maybe multi-line.
What are SQL commands?
Developers use structured query language (SQL) commands, which are specific keywords or SQL statements, to work with data stored in relational databases. The following are categories for SQL commands.
1. Data Definition Language
SQL commands used to create the database structure are known as data definition language (DDL). Based on the needs of the business, database engineers create and modify database objects using DDL. The CREATE command, for instance, is used by the database engineer to create database objects like tables, views, and indexes.
|
Command |
Description |
|---|---|
|
CREATE |
Creates a new table, a view of a table, or other object in the database. |
|
ALTER |
Modifies an existing database object, such as a table |
|
DROP |
Deletes an entire table, a view of a table, or other objects in the database |
2. Data Manipulation Language
A relational database can be updated with new data using data manipulation language (DML) statements. The INSERT command, for instance, is used by an application to add a new record to the database.
|
Command |
Description |
|---|---|
|
SELECT |
Retrieves certain records from one or more tables. |
|
INSERT |
Creates a record. |
|
UPDATE |
Modifies records. |
|
DELETE |
Deletes records. |
3. Data Query Language
Data retrieval instructions are written in the data query language (DQL), which is used to access relational databases. The SELECT command is used by software programs to filter and return particular results from a SQL table.
4. Data Control language
Data control language (DCL) is a programming language used by database administrators to control or grant other users access to databases. For instance, they can allow specific applications to manipulate one or more tables by using the GRANT command.
|
Command |
Description |
|---|---|
|
GRANT |
Gives a privilege to the user. |
|
REVOKE |
Takes back privileges granted by the user. |
5. Transaction Control Language
To automatically update databases, the relational engine uses transaction control language (TCL). For instance, the database can reverse a mistaken transaction using the ROLLBACK command.
Uses of SQL
SQL is used for interacting with databases. These interactions include:
- Data definition: It is used to define the structure and organization of the stored data and the relationships among the stored data items.
- Data retrieval: SQL can also be used for data retrieval.
- Data manipulation: If the user wants to add new data, remove data, or modifying in existing data then SQL provides this facility also.
- Access control: SQL can be used to restrict a user’s ability to retrieve, add, and modify data, protecting stored data against unauthorized access.
- Data sharing: SQL is used to coordinate data sharing by concurrent users, ensuring that changes made by one user do not inadvertently wipe out changes made at nearly the same time by another user.
SQL also differs from other computer languages because it describes what the user wants the computer to do rather than how the computer should do it. (In more technical terms, SQL is a declarative or descriptive language rather than a procedural one.)
SQL contains no IF statement for testing conditions, and no GOTO, DO, or FOR statements for program flow control. Rather, SQL statements describe how a collection of data is to be organized, or what data is to be retrieved or added to the database. The sequence of steps to do those tasks is left for the DBMS to determine.
Why SQL?
- SQL is an interactive question language. Users type SQL instructions into an interactive SQL software to retrieve facts and show them on the screen, presenting a convenient, easy-to-use device for ad hoc database queries.
- SQL is a database programming language. Programmers embed SQL instructions into their utility packages to access the facts in a database. Both user-written packages and database software packages (consisting of document writers and facts access tools) use this approach for database access.
- SQL is a client/server language. Personal computer programs use SQL to communicate over a network with database servers that save shared facts. This client/server architecture is utilized by many famous enterprise-class applications.
- SQL is Internet facts access language. Internet net servers that interact with company facts and Internet utility servers all use SQL as a widespread language for getting access to company databases, frequently through embedding SQL databases get entry to inside famous scripting languages like PHP or Perl.
- SQL is a distributed database language. Distributed database control structures use SQL to assist distribute facts throughout many linked pc structures. The DBMS software program on every gadget makes use of SQL to speak with the opposite structures, sending requests for facts to get entry to.
- SQL is a database gateway language. In a pc community with a mixture of various DBMS products, SQL is frequently utilized in a gateway that lets one logo of DBMS speak with every other logo. SQL has for this reason emerged as a useful, effective device for linking people, pc packages, and pc structures to the facts saved in a relational database.
SQL Injection
A cyberattack known as SQL injection involves tricking the database with SQL queries. To retrieve, alter, or corrupt data in a SQL database, hackers use SQL injection. To execute a SQL injection attack, for instance, they might enter a SQL query in place of a person’s name in a submission form.
What is SQL Server?
Microsoft’s relational database management system, which uses SQL to manipulate data, is formally known as SQL Server. There are various editions of the MS SQL Server, and each is tailored for particular workloads and requirements.
Finally, SQL is not a particularly structured language, especially when compared with highly structured languages such as C, Pascal, or Java. Instead, SQL statements resemble English sentences, complete with “noise words” that don’t add to the meaning of the statement but make it read more naturally. SQL has quite a few inconsistencies and also some special rules to prevent you from constructing SQL statements that look perfectly legal but that don’t make sense.
Despite the inaccuracy of its name, SQL has emerged as the standard language for using relational databases. SQL is both a powerful language and one that is relatively easy to learn. So, SQL is a database management language. The database administrator is answerable for handling a minicomputer or mainframe database and makes use of SQL to outline the database shape and manipulate get entry to the saved data.
Conclusion
SQL(Structured Query Language) is a programming language designed for managing and manipulating data stored in relational databases. It is used for interacting with DBMS like MySQL, SQL Server, Oracle, and PostgreSQL.